CODEX human healthy colon
In this tutorial we will perform a simple analysis of a published dataset from the study “Organization of the human intestine at single-cell resolution” https://doi.org/10.1038/s41586-023-05915-x The dataset along with all additional information can be downloaded here: https://datadryad.org/dataset/doi:10.5061/dryad.pk0p2ngrf It is already segmented, normalized and annotated, so we can directly start with spatial analysis.
# Import SPACEc first
import spacec as sp
# Import other libraries that will be used
import pandas as pd
import time
import scanpy as sc
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
Read in the downloaded csv file.
# Import the data from the downloaded csv file.
df = pd.read_csv("/Volumes/TK_IEO/Hickey_HubMap_small_intestine_Dataset/doi_10_5061_dryad_pk0p2ngrf__v20230913/dataset/23_09_CODEX_HuBMAP_alldata_Dryad_merged.csv")
df
| Unnamed: 0 | MUC2 | SOX9 | MUC1 | CD31 | Synapto | CD49f | CD15 | CHGA | CDX2 | ... | Cell Type em | Cell subtype | Neighborhood | Neigh_sub | Neighborhood_Ind | NeighInd_sub | Community | Major Community | Tissue Segment | Tissue Unit | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -0.303994 | -0.163727 | -0.587608 | -0.212903 | 0.164173 | -0.664863 | 0.049305 | 0.003616 | -0.377532 | ... | NK | Immune | Mature Epithelial | Epithelial | Mature Epithelial | Epithelial | Plasma Cell Enriched | Immune | Mucosa | Mucosa |
| 1 | 1 | -0.301927 | -0.491706 | -0.500804 | -0.243205 | -0.142568 | -0.664861 | -0.182627 | -0.117573 | -0.182754 | ... | NK | Immune | Transit Amplifying Zone | Epithelial | Mature Epithelial | Epithelial | Mature Epithelial | Epithelial | Mucosa | Mucosa |
| 2 | 2 | -0.302206 | -0.547234 | -0.510705 | -0.235309 | -0.217185 | -0.622758 | -0.296486 | -0.091504 | -0.268055 | ... | NK | Immune | Innate Immune Enriched | Immune | Innate Immune Enriched | Immune | Innate Immune Enriched | Immune | Mucosa | Mucosa |
| 3 | 3 | -0.304219 | -0.613068 | -0.584499 | -0.243757 | -0.266696 | -0.658449 | -0.299027 | -0.121460 | -0.345381 | ... | NK | Immune | Stroma & Innate Immune | Stromal | Stroma & Innate Immune | Stromal | Stroma | Stroma | Subucosa | Submucosa |
| 4 | 4 | -0.294644 | -0.615593 | -0.570580 | -0.247548 | -0.042246 | -0.642230 | -0.299031 | -0.121458 | -0.377533 | ... | NK | Immune | Outer Follicle | Immune | Outer Follicle | Immune | Follicle | Immune | Mucosa | Mucosa |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2603212 | 2603212 | 0.351916 | 0.693827 | -0.081489 | -0.240643 | 0.008875 | 0.143445 | 0.373710 | -0.097896 | 0.869830 | ... | CD66+ Enterocyte | Epithelial | CD66+ Mature Epithelial | Epithelial | CD66+ Mature Epithelial | Epithelial | Secretory Epithelial | Epithelial | Mucosa | Mucosa |
| 2603213 | 2603213 | 0.233642 | 0.171892 | 0.141842 | -0.236145 | -0.097772 | -0.099283 | 0.626185 | -0.105545 | 0.092076 | ... | CD66+ Enterocyte | Epithelial | CD66+ Mature Epithelial | Epithelial | CD66+ Mature Epithelial | Epithelial | Secretory Epithelial | Epithelial | Mucosa | Mucosa |
| 2603214 | 2603214 | -0.212237 | -0.280904 | -0.197833 | -0.245638 | -0.152563 | -0.125035 | 0.430416 | -0.105787 | -0.038327 | ... | CD66+ Enterocyte | Epithelial | CD8+ T Enriched IEL | Immune | CD8+ T Enriched IEL | Immune | Mature Epithelial | Epithelial | Mucosa | Mucosa |
| 2603215 | 2603215 | -0.328666 | 0.607609 | -0.180362 | -0.247351 | -0.143742 | -0.169576 | 1.095596 | -0.113879 | 0.370160 | ... | CD66+ Enterocyte | Epithelial | Transit Amplifying Zone | Epithelial | Mature Epithelial | Epithelial | CD66+ Mature Epithelial | Epithelial | Mucosa | Mucosa |
| 2603216 | 2603216 | 0.015179 | 1.656635 | -0.250193 | -0.243560 | -0.084982 | 0.061781 | 1.300252 | -0.108526 | 1.245830 | ... | CD66+ Enterocyte | Epithelial | CD66+ Mature Epithelial | Epithelial | CD66+ Mature Epithelial | Epithelial | Mature Epithelial | Epithelial | Mucosa | Mucosa |
2603217 rows × 75 columns
Convert the dataframe to an anndata object and remove unwanted columns.
# get the column index for the last marker
col_num_last_marker = df.columns.get_loc('CD161')
print(col_num_last_marker)
47
# inspect which markers work, and drop the ones that did not work from the clustering step
# make an anndata to be compatible with the downstream clustering step
adata = sp.hf.make_anndata(
df_nn = df,
col_sum = col_num_last_marker, # this is the column index that has the last protein feature # the rest will go into obs
nonFuncAb_list = ['Unnamed: 0'] # Remove the antibodies that are not working from the clustering step
)
# save the anndata object (optional)
# adata.write_h5ad("your_path/data/23_09_CODEX_HuBMAP_alldata_Dryad_merged.h5ad")
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/anndata/_core/aligned_df.py:68: ImplicitModificationWarning: Transforming to str index.
warnings.warn("Transforming to str index.", ImplicitModificationWarning)
Inspecting the dataset
# Print basic information about the AnnData object.
print("Number of cells:", adata.n_obs)
print("Number of markers:", len(adata.var_names))
print("Number of unique regions:", adata.obs["unique_region"].nunique())
print("Number of unique tissue donors:", adata.obs["donor"].nunique())
print("Number of unique cell types:", adata.obs["Cell Type"].nunique())
Number of cells: 2603217
Number of markers: 47
Number of unique regions: 66
Number of unique tissue donors: 8
Number of unique cell types: 25
adata.obs.Tissue_location.unique()
array(['Ascending', 'Descending', 'Duodenum', 'Ileum', 'Mid-jejunum',
'Proximal Jejunum', 'Descending - Sigmoid', 'Transverse'],
dtype=object)
For the purpose of this tutorial we will focus on the differences between the duodenum and the descending sigmoid colon.

https://upload.wikimedia.org/wikipedia/commons/6/62/Blausen_0603_LargeIntestine_Anatomy.png
{kind=link}
# subset the data to only include 'Duodenum' and 'Descending - Sigmoid'
adata = adata[adata.obs['Tissue_location'].isin(['Duodenum', 'Ascending'])].copy()
print("Number of cells after subsetting:", adata.n_obs)
# Print the number of cells in each tissue location
print(adata.obs['Tissue_location'].value_counts())
Number of cells after subsetting: 587379
Tissue_location
Duodenum 377540
Ascending 209839
Name: count, dtype: int64
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/anndata/_core/aligned_df.py:68: ImplicitModificationWarning: Transforming to str index.
warnings.warn("Transforming to str index.", ImplicitModificationWarning)
Reproducing the cell type annotation
The provided dataset is already annotated. This gives us the opportunity to inspect how well the clustering is capturing the annotated cell types.
# Set the random seed for reproducibility
clustering_random_seed = 0
To run the dataset fast on CPU based machines we recommend flowSOM. If you prefer Leiden clustering and have a large dataset with more than 200000 cells we recommend using the leiden_gpu implementation as it is much faster. Please notice that the leiden GPU implementation depends on Nvidia RAPIDS and is therefore only available on Linux or on Windows through WSL.
# Use this cell-type specific markers for cell type annotation
marker_list = ['MUC2', 'SOX9', 'MUC1', 'CD31', 'Synapto', 'CD49f', 'CD15', 'CHGA',
'CDX2', 'ITLN1', 'CD4', 'CD127', 'Vimentin', 'HLADR', 'CD8', 'CD11c',
'CD44', 'CD16', 'BCL2', 'CD3', 'CD123', 'CD38', 'CD90', 'aSMA', 'CD21',
'NKG2D', 'CD66', 'CD57', 'CD206', 'CD68', 'CD34', 'aDef5', 'CD7',
'CD36', 'CD138', 'CD45RO', 'Cytokeratin', 'CD117', 'CD19', 'Podoplanin',
'CD45', 'CD56', 'CD69', 'Ki67', 'CD49a', 'CD163', 'CD161']
# Start to measure time
start_time = time.time()
# clustering
adata = sp.tl.clustering(
adata,
clustering='flowSOM', # can choose between leiden and louvian
fs_xdim=10, # Width dimension of the self-organizing map (SOM) grid
fs_ydim=10, # Height dimension of the SOM grid - together with fs_xdim creates a 10x10 node grid
fs_rlen=10, # Number of training iterations for the SOM algorithm - higher values may produce more stable clusters but increase computation time
reclustering = False, # if true, no computing the neighbors and UMAP
marker_list = marker_list, #if it is None, all variable names are used for clustering
seed=clustering_random_seed, # random seed for clustering - reproducibility
key_added='flowSOM', # key to add the clustering results to adata.obs
)
# End to measure time
end_time = time.time()
print("Execution time: {:.4f} seconds".format(end_time - start_time))
Computing neighbors and UMAP
- neighbors
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
- UMAP
Clustering
FlowSOM clustering
Execution time: 374.8051 seconds
sc.pl.dotplot(adata,
marker_list, # The list of markers to show on the x-axis
'flowSOM', # The cluster column
dendrogram = True) # Show the dendrogram
WARNING: dendrogram data not found (using key=dendrogram_flowSOM). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
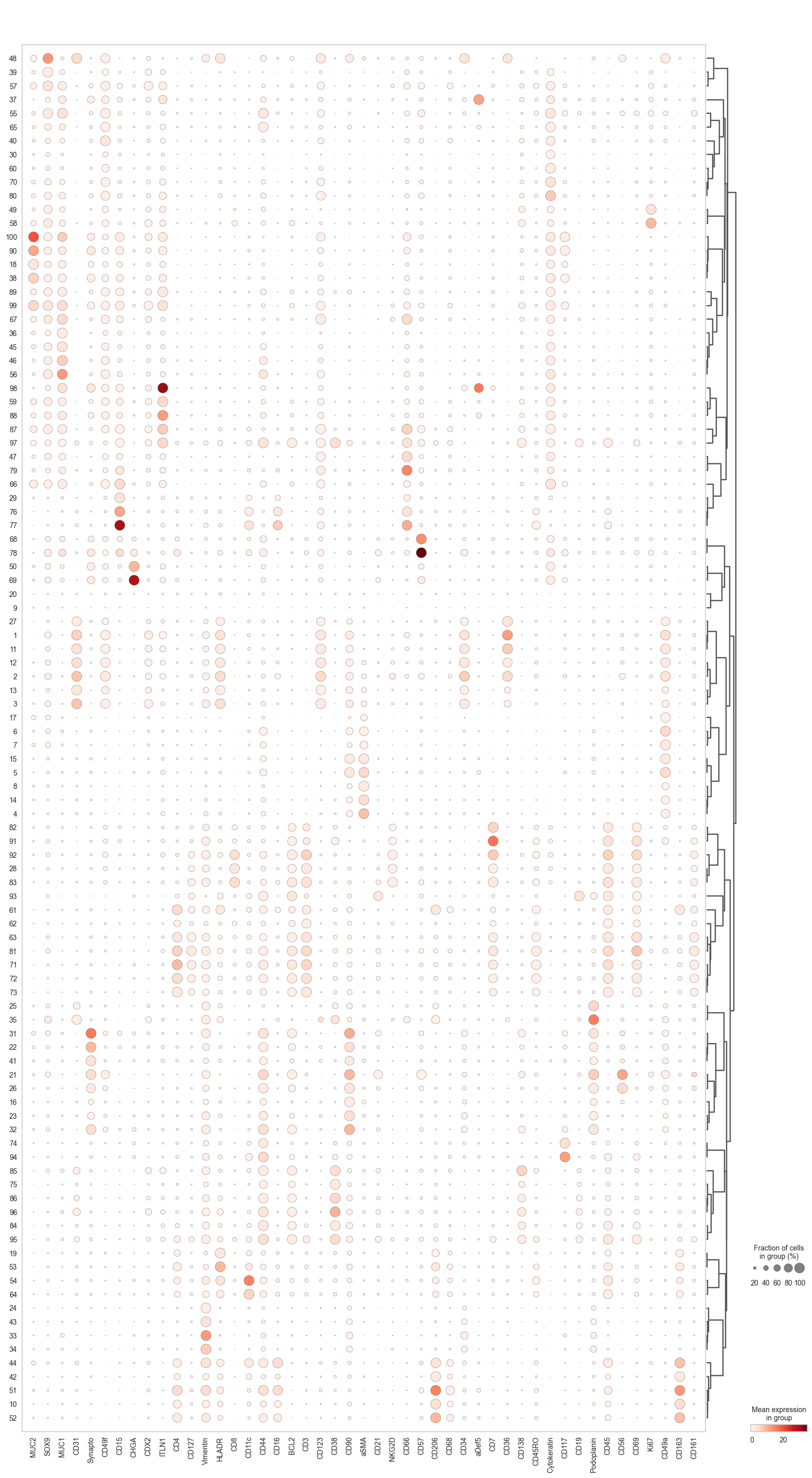
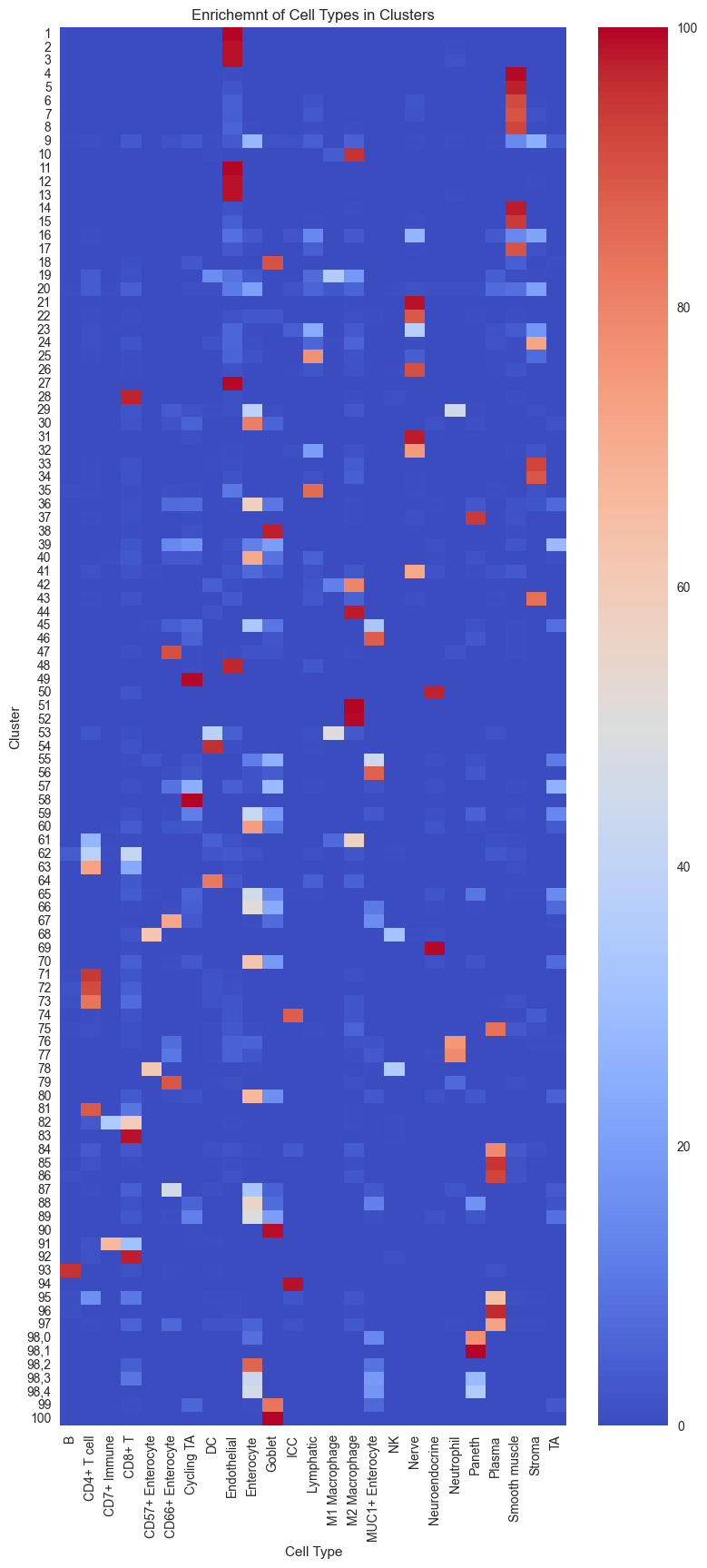
Since we already have cell types annotations in the example dataset we can compare how well our clusters capture different cell types. For a tutorial on how to manually annotate the clusters based on marker expression, have a look at notebook 3_clustering.
# Create the contingency table from adata.obs columns.
ct = pd.crosstab(adata.obs['flowSOM'], adata.obs['Cell Type'])
# Calculate the percentage of each cell type within each cluster.
percentages = ct.div(ct.sum(axis=1), axis=0) * 100
plt.figure(figsize=(9, 20))
sns.heatmap(percentages, annot=False, cmap="coolwarm")
plt.title("Enrichemnt of Cell Types in Clusters")
plt.xlabel("Cell Type")
plt.ylabel("Cluster")
plt.show()
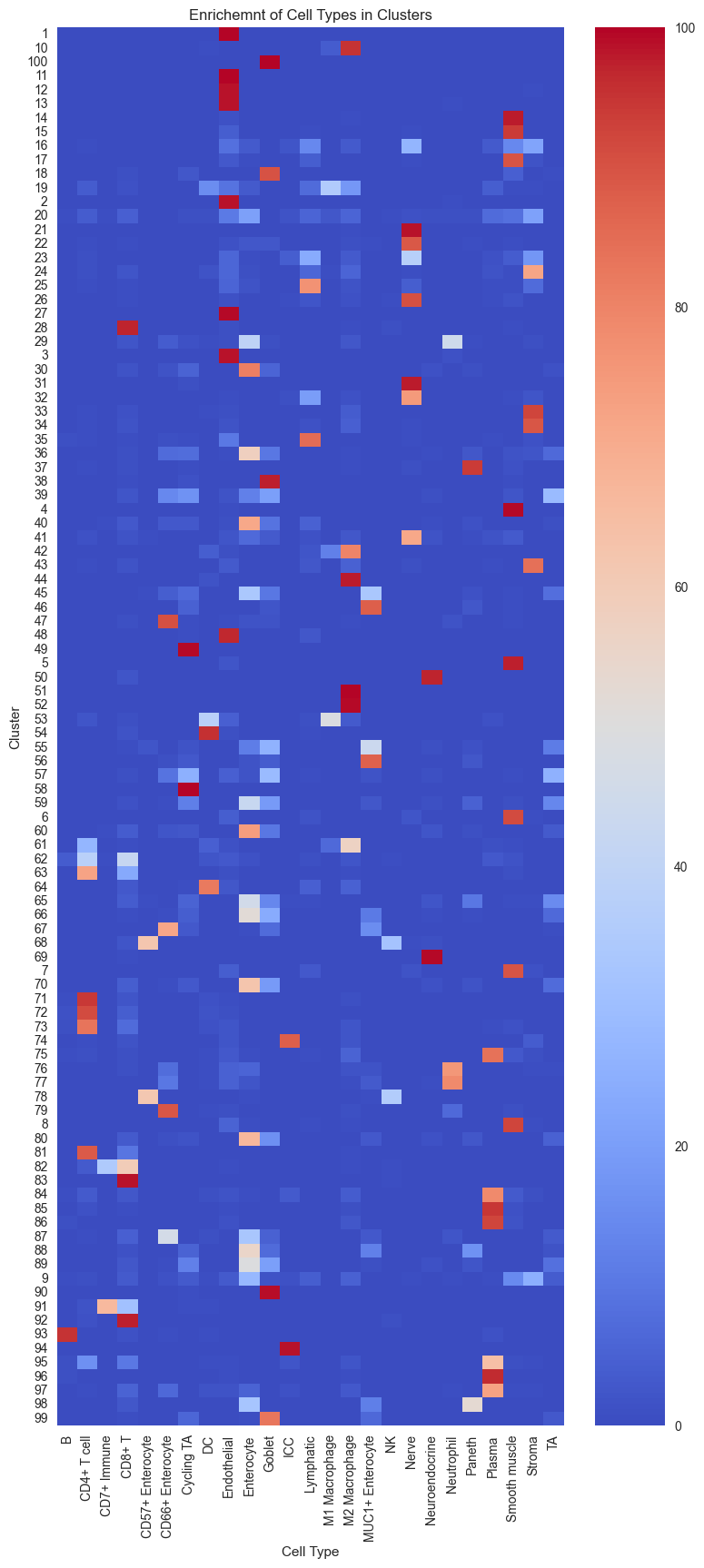
Since we performed overclustering (more clusters than cell types), we can merge multiple clusters if they show the same profile. However, we also see clusters that seem to contain multiple cell types. To resolve these mixed clusters, we can perform either an entire re-clustering with higher resolution or we sub-cluster a specific cluster (splitting the cluster in a new set of clusters).
# Start to measure time
start_time = time.time()
# subclustering cluster 0, 3, 4 sequentially (could be optional for your own data)
sc.tl.leiden(adata,
seed=clustering_random_seed, # random seed for clustering - reproducibility
restrict_to=('flowSOM',['98']), # select the cluster column name (your previously generated key) and the cluster name you want to subcluster
resolution=0.5, # resolution for subclustering
key_added='flowSOM_sub') # key added to adata.obs (keep it the same to avoid confusion and limit the adata object size)
# End to measure time
end_time = time.time()
print("Execution time: {:.4f} seconds".format(end_time - start_time))
Execution time: 0.6964 seconds
Now we can better separate the mixed cluster:
# Create the contingency table from adata.obs columns.
ct = pd.crosstab(adata.obs['flowSOM_sub'], adata.obs['Cell Type'])
# Calculate the percentage of each cell type within each cluster.
percentages = ct.div(ct.sum(axis=1), axis=0) * 100
plt.figure(figsize=(9, 20))
sns.heatmap(percentages, annot=False, cmap="coolwarm")
plt.title("Enrichemnt of Cell Types in Clusters")
plt.xlabel("Cell Type")
plt.ylabel("Cluster")
plt.show()
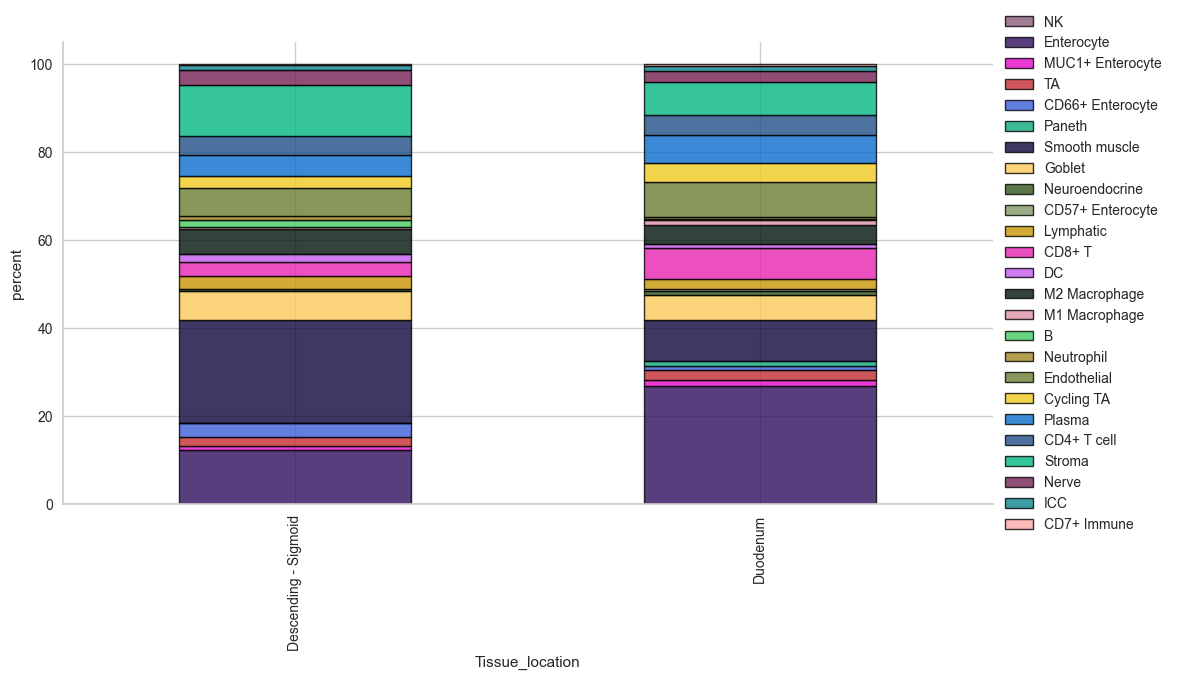
Getting insights into cell type distribution
The stacked bar plot function provides a quick overview of the cell percentages per group. The underlying object is exported as well to perform statistics in python or another software of choice.
# cell type percentage tab and visualization [much few]
ct_perc_tab, _ = sp.pl.stacked_bar_plot(
adata = adata, # adata object to use
color = 'Cell Type', # column containing the categories that are used to fill the bar plot
grouping = 'Tissue_location', # column containing a grouping variable (usually a condition or cell group)
cell_list = adata.obs['Cell Type'].unique(), # list of cell types to plot, you can also see the entire cell types adata.obs['celltype_fine'].unique()
palette=None, #default is None which means the color comes from the anndata.uns that matches the UMAP
savefig=False, # change it to true if you want to save the figure
output_fname = "", # change it to file name you prefer when saving the figure
output_dir = "output_dir", #output directory for the figure
norm = False, # if True, then whatever plotted will be scaled to sum of 1
fig_sizing= (12,6)
)
# show percentages
ct_perc_tab
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3037: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
test_freq = test1.groupby(grouping).apply(
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3063: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
melt_test.groupby(grouping)
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3074: FutureWarning: The default value of observed=False is deprecated and will change to observed=True in a future version of pandas. Specify observed=False to silence this warning and retain the current behavior
melt_test_piv = pd.pivot_table(
| Cell Type | NK | Enterocyte | MUC1+ Enterocyte | TA | CD66+ Enterocyte | Paneth | Smooth muscle | Goblet | Neuroendocrine | CD57+ Enterocyte | ... | B | Neutrophil | Endothelial | Cycling TA | Plasma | CD4+ T cell | Stroma | Nerve | ICC | CD7+ Immune |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tissue_location | |||||||||||||||||||||
| Descending - Sigmoid | 0.168867 | 12.315022 | 0.819044 | 1.971741 | 3.131373 | 0.002039 | 23.546279 | 6.531954 | 0.474376 | 0.025289 | ... | 1.573641 | 0.876556 | 6.423047 | 2.619063 | 4.704606 | 4.414188 | 11.618345 | 3.350818 | 1.116803 | 0.160709 |
| Duodenum | 0.201568 | 26.609101 | 1.533612 | 2.326641 | 0.707210 | 1.260529 | 9.258622 | 5.768660 | 0.901626 | 0.348572 | ... | 0.127139 | 0.597023 | 7.882344 | 4.259946 | 6.319595 | 4.702813 | 7.464375 | 2.435504 | 1.109816 | 0.407904 |
2 rows × 25 columns
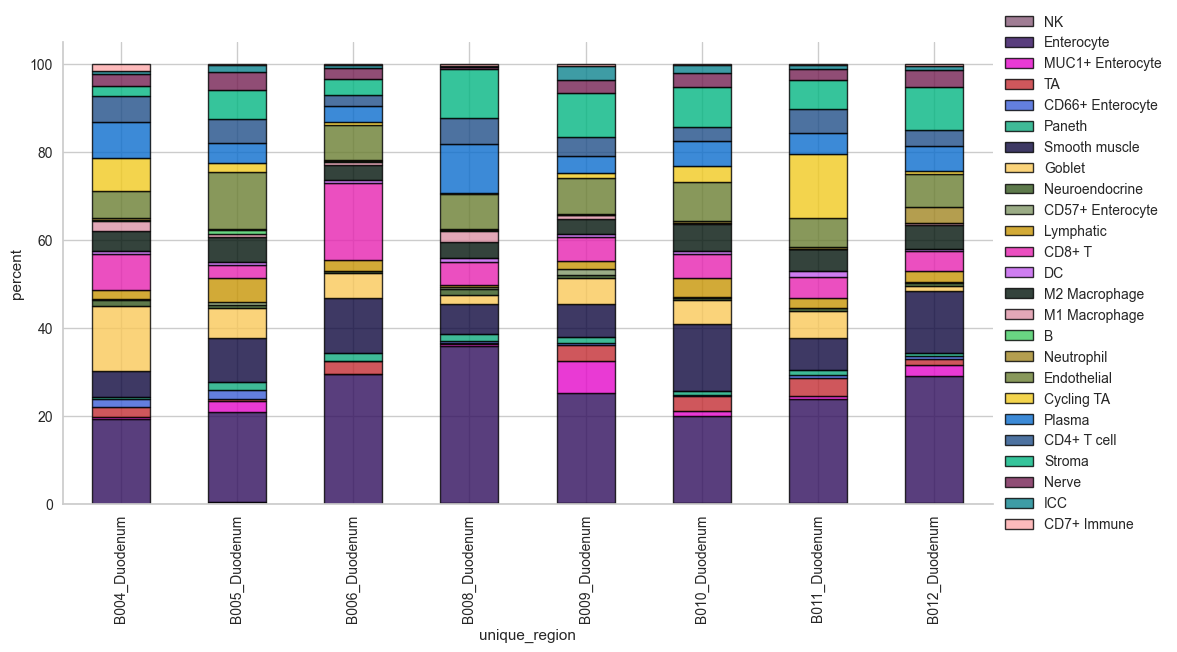
# Loop through each unique tissue region and create a plot
unique_locations = adata.obs['Tissue_location'].unique()
for loc in unique_locations:
print(f"Plotting for region: {loc}")
sp.pl.stacked_bar_plot(
adata=adata[adata.obs['Tissue_location'] == loc], # subset data for the region
color='Cell Type', # column containing the categories that are used to fill the bar plot
grouping='unique_region', # column containing a grouping variable
cell_list=adata.obs['Cell Type'].unique(), # list of cell types to plot
palette=None, # default is None which means the color comes from the anndata.uns
savefig=False, # change it to true if you want to save the figure
output_fname=f"{loc}_stacked_bar_plot.png", # file name for saving the figure
output_dir="output_dir", # output directory for the figure
norm=False, # if True, then whatever plotted will be scaled to sum of 1
fig_sizing=(12, 6)
)
Plotting for region: Duodenum
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3037: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
test_freq = test1.groupby(grouping).apply(
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3063: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
melt_test.groupby(grouping)
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3074: FutureWarning: The default value of observed=False is deprecated and will change to observed=True in a future version of pandas. Specify observed=False to silence this warning and retain the current behavior
melt_test_piv = pd.pivot_table(
Plotting for region: Descending - Sigmoid
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3037: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
test_freq = test1.groupby(grouping).apply(
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3063: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
melt_test.groupby(grouping)
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3074: FutureWarning: The default value of observed=False is deprecated and will change to observed=True in a future version of pandas. Specify observed=False to silence this warning and retain the current behavior
melt_test_piv = pd.pivot_table(

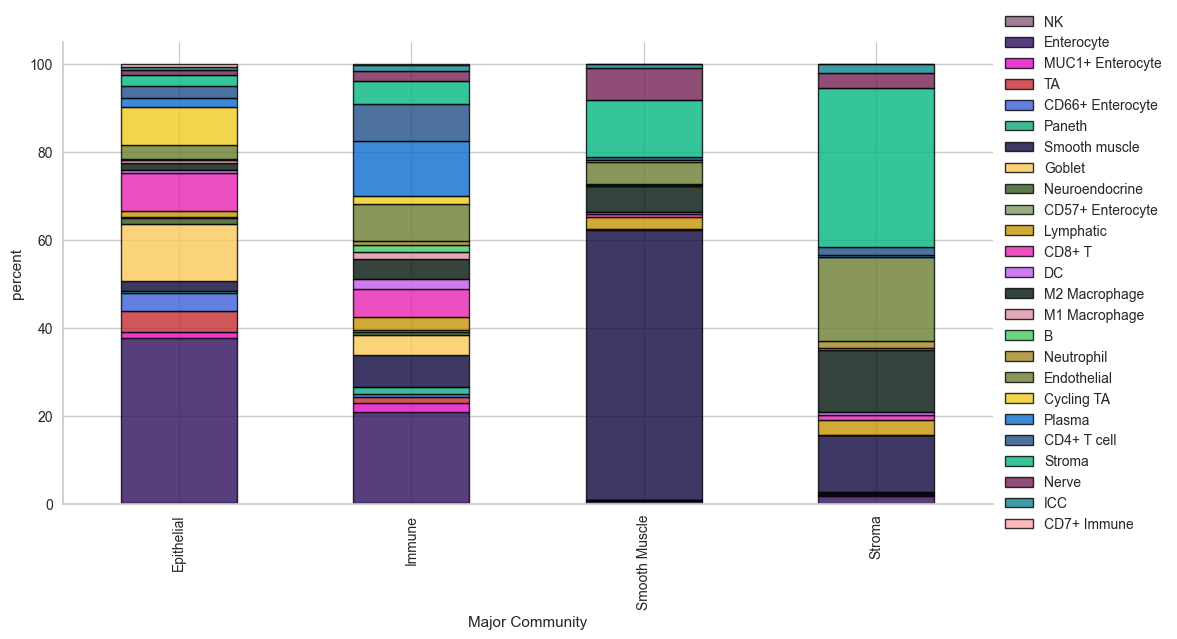
# cell type percentage tab and visualization [much few]
ct_perc_tab, _ = sp.pl.stacked_bar_plot(
adata = adata, # adata object to use
color = 'Cell Type', # column containing the categories that are used to fill the bar plot
grouping = 'Major Community', # column containing a grouping variable (usually a condition or cell group)
cell_list = adata.obs['Cell Type'].unique(), # list of cell types to plot, you can also see the entire cell types adata.obs['celltype_fine'].unique()
palette=None, #default is None which means the color comes from the anndata.uns that matches the UMAP
savefig=False, # change it to true if you want to save the figure
output_fname = "", # change it to file name you prefer when saving the figure
output_dir = "output_dir", #output directory for the figure
norm = False, # if True, then whatever plotted will be scaled to sum of 1
fig_sizing= (12,6)
)
# show percentages
ct_perc_tab
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3037: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
test_freq = test1.groupby(grouping).apply(
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3063: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
melt_test.groupby(grouping)
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/plotting/_general.py:3074: FutureWarning: The default value of observed=False is deprecated and will change to observed=True in a future version of pandas. Specify observed=False to silence this warning and retain the current behavior
melt_test_piv = pd.pivot_table(
| Cell Type | NK | Enterocyte | MUC1+ Enterocyte | TA | CD66+ Enterocyte | Paneth | Smooth muscle | Goblet | Neuroendocrine | CD57+ Enterocyte | ... | B | Neutrophil | Endothelial | Cycling TA | Plasma | CD4+ T cell | Stroma | Nerve | ICC | CD7+ Immune |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Major Community | |||||||||||||||||||||
| Epithelial | 0.161610 | 37.679507 | 1.355490 | 4.756104 | 4.115486 | 0.471243 | 2.195573 | 12.908940 | 1.269589 | 0.261586 | ... | 0.045134 | 0.324677 | 3.203576 | 8.585738 | 2.040757 | 2.644976 | 2.636241 | 1.077888 | 0.667796 | 0.638192 |
| Immune | 0.280478 | 20.737929 | 1.939399 | 1.456782 | 0.653502 | 1.486818 | 7.420291 | 4.415806 | 0.780955 | 0.336899 | ... | 1.705599 | 0.866600 | 8.316928 | 1.787186 | 12.491628 | 8.588882 | 5.208126 | 2.183752 | 1.333793 | 0.236641 |
| Smooth Muscle | 0.058673 | 0.638322 | 0.058673 | 0.184112 | 0.055638 | 0.036418 | 61.333495 | 0.237727 | 0.024278 | 0.003035 | ... | 0.011128 | 0.443082 | 4.899194 | 0.349003 | 0.144659 | 0.678786 | 12.796779 | 7.355366 | 0.903362 | 0.011128 |
| Stroma | 0.130188 | 1.807237 | 0.236579 | 0.065794 | 0.282775 | 0.131588 | 12.944635 | 0.111990 | 0.004200 | 0.008399 | ... | 0.044796 | 1.625254 | 18.999090 | 0.090992 | 0.377966 | 1.814237 | 36.049556 | 3.552880 | 1.922027 | 0.034997 |
4 rows × 25 columns
sp.pl.catplot(
adata,
color = "Cell Type", # specify group column name here (e.g. celltype_fine)
unique_region = "unique_region", # specify unique_regions here
X='x', Y='y', # specify x and y columns here
n_columns=3, # adjust the number of columns for plotting here (how many plots do you want in one row?)
palette=None, #default is None which means the color comes from the anndata.uns that matches the UMAP
savefig=False, # save figure as pdf
output_fname = "", # change it to file name you prefer when saving the figure
output_dir="output_dir", # specify output directory here (if savefig=True)
figsize= 17,
size = 20)
| x | y | Cell Type | unique_region | |
|---|---|---|---|---|
| 2192275 | 583.0 | 8076.0 | Cycling TA | B012_Sigmoid |
| 2192276 | 1092.0 | 3971.0 | Cycling TA | B012_Sigmoid |
| 2192277 | 830.0 | 5034.0 | Cycling TA | B012_Sigmoid |
| 2192278 | 1278.0 | 7631.0 | Cycling TA | B012_Sigmoid |
| 2192279 | 628.0 | 2757.0 | Cycling TA | B012_Sigmoid |
| ... | ... | ... | ... | ... |
| 2329692 | 7825.0 | 7398.0 | DC | B012_Sigmoid |
| 2329693 | 4960.0 | 5855.0 | DC | B012_Sigmoid |
| 2329694 | 6684.0 | 2653.0 | DC | B012_Sigmoid |
| 2329695 | 5280.0 | 8654.0 | DC | B012_Sigmoid |
| 2329696 | 8860.0 | 8778.0 | DC | B012_Sigmoid |
51593 rows × 4 columns

Identifying spatial neighborhoods
CN analysis involves four main steps: first, a window is drawn around each cell, encompassing the centered cell and its n nearest neighbors. For instance, a window size of 10 was chosen, resulting in each window containing the centered cell and its nine nearest neighbors. In the subsequent step, the function quantifies the number and identities of cell types within the windows, and represents the window composition as a vector. Next, all vectors are clustered into a predefined number of CNs. For example, in this analysis, the cells were clustered into 20 neighborhoods. Finally, identities are assigned to each cluster based on its cellular composition. Depending on the sample’s cellular complexity, it might be necessary to initially overcluster and then subsequently merge clusters. Depending on the chosen window size, neighborhood analysis can describe microstructures within tissue or broader macrostructures. For example, a window size of 10 was found to be suitable for detecting local neighborhoods of recurring identity.
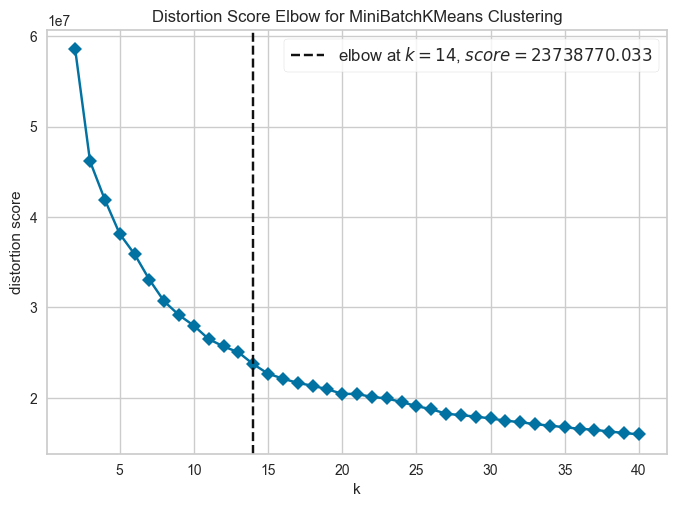
If you are unsure how many neighborhoods to expect, the elbow parameter can be set to True. If set to True, the function tests 1-n_neighborhoods and creates an elbow plot that helps to discriminate how unique the clusters are and what is the optimal cutoff point to get the largest number of unique cluster (CN) without unnecessarily increasing the number of neighborhoods.
# compute for CNs
# tune k and n_neighborhoods to obtain the best result
adata = sp.tl.neighborhood_analysis(
adata,
unique_region = "unique_region",
cluster_col = "Cell Type",
X = 'x', Y = 'y',
k = 10, # k nearest neighbors
n_neighborhoods = 40, #number of CNs
elbow = True)
Starting: 1/66 : B004_Ascending
Finishing: 1/66 : B004_Ascending 0.059689998626708984 0.061428070068359375
Starting: 9/66 : B004_Descending
Finishing: 9/66 : B004_Descending 0.04340505599975586 0.10492491722106934
Starting: 51/66 : B004_Descending - Sigmoid
Finishing: 51/66 : B004_Descending - Sigmoid 0.033477067947387695 0.13866806030273438
Starting: 18/66 : B004_Duodenum
Finishing: 18/66 : B004_Duodenum 0.06085705757141113 0.19963407516479492
Starting: 25/66 : B004_Ileum
Finishing: 25/66 : B004_Ileum 0.036824941635131836 0.23711109161376953
Starting: 34/66 : B004_Mid-jejunum
Finishing: 34/66 : B004_Mid-jejunum 0.04678702354431152 0.2844710350036621
Starting: 42/66 : B004_Proximal Jejunum
Finishing: 42/66 : B004_Proximal Jejunum 0.0417327880859375 0.32633495330810547
Starting: 59/66 : B004_Transverse
Finishing: 59/66 : B004_Transverse 0.055433034896850586 0.38189697265625
Starting: 2/66 : B005_Ascending
Finishing: 2/66 : B005_Ascending 0.023382186889648438 0.4059572219848633
Starting: 10/66 : B005_Descending
Finishing: 10/66 : B005_Descending 0.07724380493164062 0.48328709602355957
Starting: 52/66 : B005_Descending - Sigmoid
Finishing: 52/66 : B005_Descending - Sigmoid 0.049818992614746094 0.5336649417877197
Starting: 17/66 : B005_Duodenum
Finishing: 17/66 : B005_Duodenum 0.04752206802368164 0.5823540687561035
Starting: 26/66 : B005_Ileum
Finishing: 26/66 : B005_Ileum 0.02525019645690918 0.6077580451965332
Starting: 35/66 : B005_Mid-jejunum
Finishing: 35/66 : B005_Mid-jejunum 0.16119694709777832 0.7690439224243164
Starting: 43/66 : B005_Proximal Jejunum
Finishing: 43/66 : B005_Proximal Jejunum 0.054959774017333984 0.825009822845459
Starting: 60/66 : B005_Transverse
Finishing: 60/66 : B005_Transverse 0.04841113090515137 0.8743090629577637
Starting: 3/66 : B006_Ascending
Finishing: 3/66 : B006_Ascending 0.05823993682861328 0.9326920509338379
Starting: 11/66 : B006_Descending
Finishing: 11/66 : B006_Descending 0.02979111671447754 0.9627852439880371
Starting: 53/66 : B006_Descending - Sigmoid
Finishing: 53/66 : B006_Descending - Sigmoid 0.037706851959228516 1.0005841255187988
Starting: 19/66 : B006_Duodenum
Finishing: 19/66 : B006_Duodenum 0.12288904190063477 1.1237671375274658
Starting: 27/66 : B006_Ileum
Finishing: 27/66 : B006_Ileum 0.14852190017700195 1.2733030319213867
Starting: 33/66 : B006_Mid-jejunum
Finishing: 33/66 : B006_Mid-jejunum 0.051239013671875 1.3264930248260498
Starting: 44/66 : B006_Proximal Jejunum
Finishing: 44/66 : B006_Proximal Jejunum 0.05868220329284668 1.385411024093628
Starting: 61/66 : B006_Transverse
Finishing: 61/66 : B006_Transverse 0.04161524772644043 1.4272971153259277
Starting: 24/66 : B008_Duodenum
Finishing: 24/66 : B008_Duodenum 0.11412405967712402 1.5415270328521729
Starting: 32/66 : B008_Ileum
Finishing: 32/66 : B008_Ileum 0.052716970443725586 1.5947389602661133
Starting: 16/66 : B008_Left
Finishing: 16/66 : B008_Left 0.053468942642211914 1.6484956741333008
Starting: 41/66 : B008_Mid jejunum
Finishing: 41/66 : B008_Mid jejunum 0.07924413681030273 1.728085994720459
Starting: 49/66 : B008_Proximal jejunum
Finishing: 49/66 : B008_Proximal jejunum 0.05491471290588379 1.7832987308502197
Starting: 50/66 : B008_Proximal jejunum_extra
Finishing: 50/66 : B008_Proximal jejunum_extra 0.04814577102661133 1.8318939208984375
Starting: 8/66 : B008_Right
Finishing: 8/66 : B008_Right 0.008453845977783203 1.840566873550415
Starting: 58/66 : B008_Sigmoid
Finishing: 58/66 : B008_Sigmoid 0.06219196319580078 1.9027929306030273
Starting: 66/66 : B008_Trans
Finishing: 66/66 : B008_Trans 0.030678987503051758 1.9341740608215332
Starting: 20/66 : B009_Duodenum
Finishing: 20/66 : B009_Duodenum 0.06216001510620117 1.996424913406372
Starting: 28/66 : B009_Ileum
Finishing: 28/66 : B009_Ileum 0.13092398643493652 2.128166913986206
Starting: 12/66 : B009_Left
Finishing: 12/66 : B009_Left 0.1118168830871582 2.2411088943481445
Starting: 36/66 : B009_Mid jejunum
Finishing: 36/66 : B009_Mid jejunum 0.1297459602355957 2.371269941329956
Starting: 37/66 : B009_Mid jejunum_extra
Finishing: 37/66 : B009_Mid jejunum_extra 0.12656497955322266 2.49812912940979
Starting: 46/66 : B009_Proximal jejunum
Finishing: 46/66 : B009_Proximal jejunum 0.07380080223083496 2.5725150108337402
Starting: 4/66 : B009_Right
Finishing: 4/66 : B009_Right 0.09087896347045898 2.6635730266571045
Starting: 54/66 : B009_Sigmoid
Finishing: 54/66 : B009_Sigmoid 0.058786869049072266 2.7226619720458984
Starting: 62/66 : B009_Trans
Finishing: 62/66 : B009_Trans 0.047174930572509766 2.7702767848968506
Starting: 23/66 : B010_Duodenum
Finishing: 23/66 : B010_Duodenum 0.046092987060546875 2.8168530464172363
Starting: 29/66 : B010_Ileum
Finishing: 29/66 : B010_Ileum 0.055780649185180664 2.873121976852417
Starting: 15/66 : B010_Left
Finishing: 15/66 : B010_Left 0.026739835739135742 2.900448799133301
Starting: 40/66 : B010_Mid jejunum
Finishing: 40/66 : B010_Mid jejunum 0.04383420944213867 2.9447450637817383
Starting: 47/66 : B010_Proximal jejunum
Finishing: 47/66 : B010_Proximal jejunum 0.08380889892578125 3.0293757915496826
Starting: 5/66 : B010_Right
Finishing: 5/66 : B010_Right 0.033061981201171875 3.0627479553222656
Starting: 56/66 : B010_Sigmoid
Finishing: 56/66 : B010_Sigmoid 0.03583979606628418 3.0987119674682617
Starting: 63/66 : B010_Trans
Finishing: 63/66 : B010_Trans 0.022043943405151367 3.1208770275115967
Starting: 21/66 : B011_Duodenum
Finishing: 21/66 : B011_Duodenum 0.16418695449829102 3.2856359481811523
Starting: 30/66 : B011_Ileum
Finishing: 30/66 : B011_Ileum 0.04619002342224121 3.3321800231933594
Starting: 14/66 : B011_Left
Finishing: 14/66 : B011_Left 0.02861309051513672 3.360905170440674
Starting: 38/66 : B011_Mid jejunum
Finishing: 38/66 : B011_Mid jejunum 0.06306886672973633 3.4240670204162598
Starting: 45/66 : B011_Proximal jejunum
Finishing: 45/66 : B011_Proximal jejunum 0.04290199279785156 3.4671311378479004
Starting: 6/66 : B011_Right
Finishing: 6/66 : B011_Right 0.028042316436767578 3.49546217918396
Starting: 55/66 : B011_Sigmoid
Finishing: 55/66 : B011_Sigmoid 0.0289309024810791 3.5246219635009766
Starting: 64/66 : B011_Trans
Finishing: 64/66 : B011_Trans 0.042402029037475586 3.567108154296875
Starting: 22/66 : B012_Duodenum
Finishing: 22/66 : B012_Duodenum 0.04102301597595215 3.6084611415863037
Starting: 31/66 : B012_Ileum
Finishing: 31/66 : B012_Ileum 0.0457911491394043 3.6545279026031494
Starting: 13/66 : B012_Left
Finishing: 13/66 : B012_Left 0.13162612915039062 3.7862720489501953
Starting: 39/66 : B012_Mid jejunum
Finishing: 39/66 : B012_Mid jejunum 0.09508705139160156 3.8822691440582275
Starting: 48/66 : B012_Proximal jejunum
Finishing: 48/66 : B012_Proximal jejunum 0.04413795471191406 3.927340030670166
Starting: 7/66 : B012_Right
Finishing: 7/66 : B012_Right 0.0377349853515625 3.965256929397583
Starting: 57/66 : B012_Sigmoid
Finishing: 57/66 : B012_Sigmoid 0.08191800117492676 4.047350168228149
Starting: 65/66 : B012_Trans
Finishing: 65/66 : B012_Trans 0.04225611686706543 4.090313196182251
# compute for CNs
# tune k and n_neighborhoods to obtain the best result
adata = sp.tl.neighborhood_analysis(
adata,
unique_region = "unique_region", # regions or samples
cluster_col = "Cell Type", # derive clusters from this column
X = 'x', Y = 'y', # spatial coordinates
k = 10, # k nearest neighbors
n_neighborhoods = 30, # number of CNs (or max number of CNs for elbow plot)
elbow = False) # if True, will plot the elbow plot
Starting: 1/66 : B004_Ascending
Finishing: 1/66 : B004_Ascending 0.06076407432556152 0.06228184700012207
Starting: 9/66 : B004_Descending
Finishing: 9/66 : B004_Descending 0.0442047119140625 0.10717892646789551
Starting: 51/66 : B004_Descending - Sigmoid
Finishing: 51/66 : B004_Descending - Sigmoid 0.034211158752441406 0.14211606979370117
Starting: 18/66 : B004_Duodenum
Finishing: 18/66 : B004_Duodenum 0.058167219161987305 0.2004561424255371
Starting: 25/66 : B004_Ileum
Finishing: 25/66 : B004_Ileum 0.03582906723022461 0.23684406280517578
Starting: 34/66 : B004_Mid-jejunum
Finishing: 34/66 : B004_Mid-jejunum 0.0450589656829834 0.2822530269622803
Starting: 42/66 : B004_Proximal Jejunum
Finishing: 42/66 : B004_Proximal Jejunum 0.05440497398376465 0.3369460105895996
Starting: 59/66 : B004_Transverse
Finishing: 59/66 : B004_Transverse 0.05406594276428223 0.3930988311767578
Starting: 2/66 : B005_Ascending
Finishing: 2/66 : B005_Ascending 0.023790836334228516 0.41808080673217773
Starting: 10/66 : B005_Descending
Finishing: 10/66 : B005_Descending 0.07785987854003906 0.4963409900665283
Starting: 52/66 : B005_Descending - Sigmoid
Finishing: 52/66 : B005_Descending - Sigmoid 0.019664287567138672 0.5167531967163086
Starting: 17/66 : B005_Duodenum
Finishing: 17/66 : B005_Duodenum 0.03266191482543945 0.5497620105743408
Starting: 26/66 : B005_Ileum
Finishing: 26/66 : B005_Ileum 0.02278876304626465 0.5727207660675049
Starting: 35/66 : B005_Mid-jejunum
Finishing: 35/66 : B005_Mid-jejunum 0.12826800346374512 0.7011168003082275
Starting: 43/66 : B005_Proximal Jejunum
Finishing: 43/66 : B005_Proximal Jejunum 0.052947998046875 0.7547519207000732
Starting: 60/66 : B005_Transverse
Finishing: 60/66 : B005_Transverse 0.044783830642700195 0.7999980449676514
Starting: 3/66 : B006_Ascending
Finishing: 3/66 : B006_Ascending 0.053945064544677734 0.8540940284729004
Starting: 11/66 : B006_Descending
Finishing: 11/66 : B006_Descending 0.027484893798828125 0.8818371295928955
Starting: 53/66 : B006_Descending - Sigmoid
Finishing: 53/66 : B006_Descending - Sigmoid 0.0353391170501709 0.9173378944396973
Starting: 19/66 : B006_Duodenum
Finishing: 19/66 : B006_Duodenum 0.08684301376342773 1.0043342113494873
Starting: 27/66 : B006_Ileum
Finishing: 27/66 : B006_Ileum 0.13814401626586914 1.1431770324707031
Starting: 33/66 : B006_Mid-jejunum
Finishing: 33/66 : B006_Mid-jejunum 0.052201032638549805 1.1967360973358154
Starting: 44/66 : B006_Proximal Jejunum
Finishing: 44/66 : B006_Proximal Jejunum 0.059844017028808594 1.2572190761566162
Starting: 61/66 : B006_Transverse
Finishing: 61/66 : B006_Transverse 0.0427398681640625 1.3004961013793945
Starting: 24/66 : B008_Duodenum
Finishing: 24/66 : B008_Duodenum 0.11915397644042969 1.4199581146240234
Starting: 32/66 : B008_Ileum
Finishing: 32/66 : B008_Ileum 0.05185103416442871 1.472952127456665
Starting: 16/66 : B008_Left
Finishing: 16/66 : B008_Left 0.051358938217163086 1.5246648788452148
Starting: 41/66 : B008_Mid jejunum
Finishing: 41/66 : B008_Mid jejunum 0.07873106002807617 1.603632926940918
Starting: 49/66 : B008_Proximal jejunum
Finishing: 49/66 : B008_Proximal jejunum 0.05563616752624512 1.6597211360931396
Starting: 50/66 : B008_Proximal jejunum_extra
Finishing: 50/66 : B008_Proximal jejunum_extra 0.04876208305358887 1.7090380191802979
Starting: 8/66 : B008_Right
Finishing: 8/66 : B008_Right 0.008089065551757812 1.7175111770629883
Starting: 58/66 : B008_Sigmoid
Finishing: 58/66 : B008_Sigmoid 0.06847405433654785 1.7860119342803955
Starting: 66/66 : B008_Trans
Finishing: 66/66 : B008_Trans 0.03075718879699707 1.8170340061187744
Starting: 20/66 : B009_Duodenum
Finishing: 20/66 : B009_Duodenum 0.06059694290161133 1.8778119087219238
Starting: 28/66 : B009_Ileum
Finishing: 28/66 : B009_Ileum 0.17436504364013672 2.0527420043945312
Starting: 12/66 : B009_Left
Finishing: 12/66 : B009_Left 0.11438417434692383 2.168377161026001
Starting: 36/66 : B009_Mid jejunum
Finishing: 36/66 : B009_Mid jejunum 0.13514304161071777 2.3047611713409424
Starting: 37/66 : B009_Mid jejunum_extra
Finishing: 37/66 : B009_Mid jejunum_extra 0.08666205406188965 2.392193078994751
Starting: 46/66 : B009_Proximal jejunum
Finishing: 46/66 : B009_Proximal jejunum 0.08600282669067383 2.4790289402008057
Starting: 4/66 : B009_Right
Finishing: 4/66 : B009_Right 0.0928032398223877 2.572681188583374
Starting: 54/66 : B009_Sigmoid
Finishing: 54/66 : B009_Sigmoid 0.058149099349975586 2.6315701007843018
Starting: 62/66 : B009_Trans
Finishing: 62/66 : B009_Trans 0.04633593559265137 2.6784369945526123
Starting: 23/66 : B010_Duodenum
Finishing: 23/66 : B010_Duodenum 0.047650814056396484 2.726404905319214
Starting: 29/66 : B010_Ileum
Finishing: 29/66 : B010_Ileum 0.05690503120422363 2.783784866333008
Starting: 15/66 : B010_Left
Finishing: 15/66 : B010_Left 0.02668023109436035 2.8107478618621826
Starting: 40/66 : B010_Mid jejunum
Finishing: 40/66 : B010_Mid jejunum 0.042333126068115234 2.85345196723938
Starting: 47/66 : B010_Proximal jejunum
Finishing: 47/66 : B010_Proximal jejunum 0.0816650390625 2.9354727268218994
Starting: 5/66 : B010_Right
Finishing: 5/66 : B010_Right 0.03181815147399902 2.9681549072265625
Starting: 56/66 : B010_Sigmoid
Finishing: 56/66 : B010_Sigmoid 0.034158945083618164 3.00249981880188
Starting: 63/66 : B010_Trans
Finishing: 63/66 : B010_Trans 0.020938873291015625 3.0235629081726074
Starting: 21/66 : B011_Duodenum
Finishing: 21/66 : B011_Duodenum 0.09783506393432617 3.1216180324554443
Starting: 30/66 : B011_Ileum
Finishing: 30/66 : B011_Ileum 0.045098066329956055 3.1678450107574463
Starting: 14/66 : B011_Left
Finishing: 14/66 : B011_Left 0.027835845947265625 3.1960878372192383
Starting: 38/66 : B011_Mid jejunum
Finishing: 38/66 : B011_Mid jejunum 0.10292720794677734 3.299206018447876
Starting: 45/66 : B011_Proximal jejunum
Finishing: 45/66 : B011_Proximal jejunum 0.04195880889892578 3.3414318561553955
Starting: 6/66 : B011_Right
Finishing: 6/66 : B011_Right 0.027364015579223633 3.3693089485168457
Starting: 55/66 : B011_Sigmoid
Finishing: 55/66 : B011_Sigmoid 0.028815031051635742 3.398221015930176
Starting: 64/66 : B011_Trans
Finishing: 64/66 : B011_Trans 0.043810129165649414 3.442509174346924
Starting: 22/66 : B012_Duodenum
Finishing: 22/66 : B012_Duodenum 0.04270195960998535 3.4856250286102295
Starting: 31/66 : B012_Ileum
Finishing: 31/66 : B012_Ileum 0.05138993263244629 3.537371873855591
Starting: 13/66 : B012_Left
Finishing: 13/66 : B012_Left 0.10940003395080566 3.647063970565796
Starting: 39/66 : B012_Mid jejunum
Finishing: 39/66 : B012_Mid jejunum 0.09380578994750977 3.7416858673095703
Starting: 48/66 : B012_Proximal jejunum
Finishing: 48/66 : B012_Proximal jejunum 0.04753875732421875 3.789813995361328
Starting: 7/66 : B012_Right
Finishing: 7/66 : B012_Right 0.044606924057006836 3.834651231765747
Starting: 57/66 : B012_Sigmoid
Finishing: 57/66 : B012_Sigmoid 0.0808708667755127 3.9161527156829834
Starting: 65/66 : B012_Trans
Finishing: 65/66 : B012_Trans 0.040596961975097656 3.95739483833313
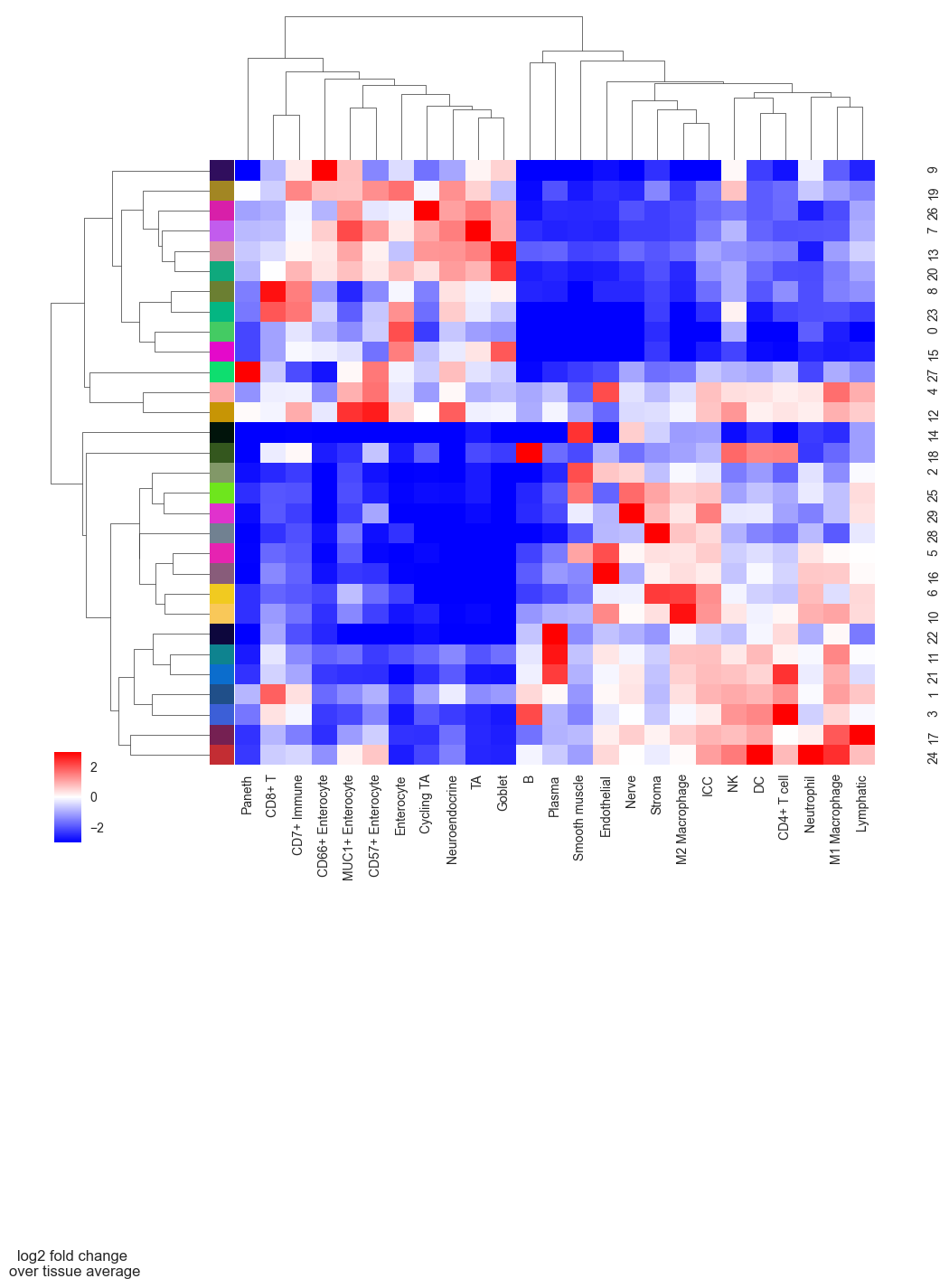
# plot CN to see what cell types are enriched per CN so that we can annotate them better
sp.pl.cn_exp_heatmap(
adata, # anndata
cluster_col = "Cell Type", # cell type column
cn_col = "CN_k10_n30", # CN column
palette=None, # color palette for CN
savefig = False, # save the figure
output_dir = "output_dir", # output directory
rand_seed = 1, # random seed for reproducibility
figsize = (10, 10), # figure size
)
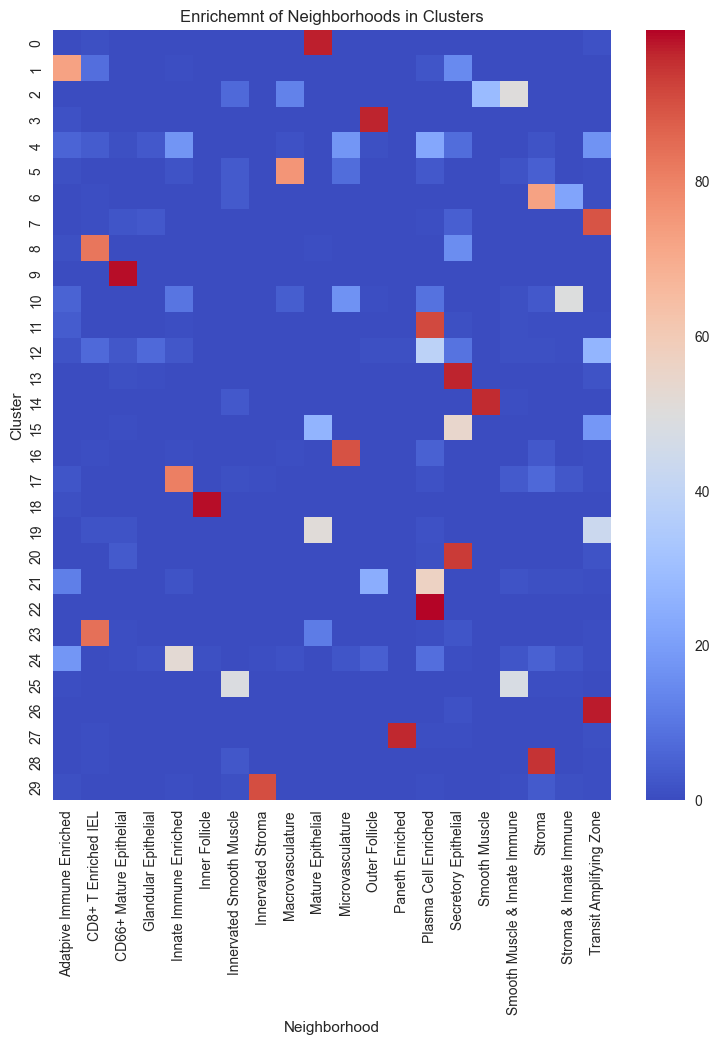
# Create the contingency table from adata.obs columns.
ct = pd.crosstab(adata.obs['CN_k10_n30'], adata.obs['Neighborhood'])
# Calculate the percentage of each cell type within each cluster.
percentages = ct.div(ct.sum(axis=1), axis=0) * 100
plt.figure(figsize=(9, 10))
sns.heatmap(percentages, annot=False, cmap="coolwarm")
plt.title("Enrichemnt of Neighborhoods in Clusters")
plt.xlabel("Neighborhood")
plt.ylabel("Cluster")
plt.show()
Perform Cell-Cell distance analysis
# Start to measure time
start_time = time.time()
# compute the potential interactions
distance_pvals, results_dict = sp.tl.identify_interactions(
adata = adata, # AnnData object
cellid = "index", # column that contains the cell id (set index if the cell id is the index of the dataframe)
x_pos = "x", # x coordinate column
y_pos = "y", # y coordinate column
cell_type = "Community", # column that contains the cell type information
region = "unique_region", # column that contains the region information
num_iterations=1000, # number of iterations for the permutation test
num_cores=10, # number of CPU threads to use
min_observed = 10, # minimum number of observed interactions to consider a cell type pair
comparison = 'Tissue_location', # column that contains the condition information we want to compare
distance_threshold=100) # distance threshold in px (20 µm)
# End to measure time
end_time = time.time()
print("Execution time: {:.4f} seconds".format(end_time - start_time))
index is not in the adata.obs, use index as cellid instead!
Computing for observed distances between cell types!
This function expects integer values for xy coordinates.
x and y will be changed to integer. Please check the generated output!
Save triangulation distances output to anndata.uns triDist
Permuting data labels to obtain the randomly distributed distances!
this step can take awhile
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/tools/_general.py:1328: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
triangulation_distances[column].fillna("Unknown", inplace=True)
/Users/timkempchen/mambaforge/envs/spacec_dev/lib/python3.10/site-packages/spacec/tools/_general.py:1328: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
triangulation_distances[column].fillna("Unknown", inplace=True)
Execution time: 589.5555 seconds
After calculating the observed and expected distances the data can be filtered to only include the most significant hits. When comparing the real distances to the shuffled distances it is important to consider the overall frequency of a cell type. Rare cell types are often over represented as a small change already causes a hugh difference in numbers. Due to that we generally recommend to exclude rare cell types from this analysis. The default threshold is set to 1%, however, it can be adjusted.
distance_pvals_filt = sp.tl.remove_rare_cell_types(adata,
distance_pvals,
cell_type_column="Community",
min_cell_type_percentage=1)
Cell types that belong to less than 1% of total cells:
[], Categories (10, object): ['Adaptive Immune Enriched', 'CD8+ T Enriched IEL', 'CD66+ Mature Epithelial', 'Follicle', ..., 'Plasma Cell Enriched', 'Secretory Epithelial', 'Smooth Muscle', 'Stroma']
# Identify significant cell-cell interactions
# dist_table_filt is a simplified table used for plotting
# dist_data_filt contains the filtered raw data with more information about the pairs
# The function outputs two dataframes: and dist_data_filt that contains all filtered interactions and dist_table_filt that contains a table for all interactions that show a significant value in both tissues
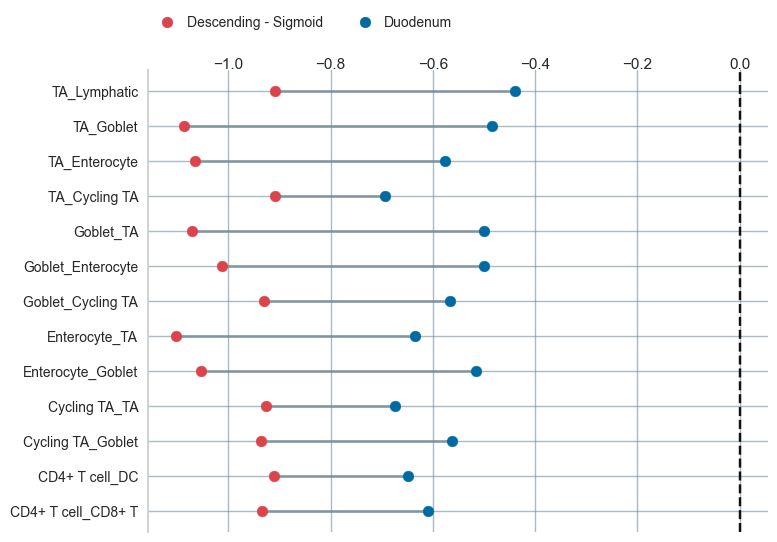
dist_table_filt, dist_data_filt = sp.tl.filter_interactions(
distance_pvals = distance_pvals_filt,
pvalue = 0.05,
logfold_group_abs = 0.9,
comparison = 'Tissue_location')
print(dist_table_filt.shape)
dist_data_filt
(0, 0)
| celltype1 | celltype2 | Tissue_location | expected | expected_mean | keep_x | observed | observed_mean | keep_y | pvalue | logfold_group | interaction | logfold_group_abs | pairs |
|---|
sp.pl.dumbbell(data = dist_table_filt, figsize=(8,6), colors = ['#DB444B', '#006BA2'],)